March 7, 2026
Re-Forge: How We Built a Prose Refinement Engine
We ran 35 controlled experiments to answer a hard question: can a second AI pass reliably improve fiction? Here’s what failed, what broke catastrophically, and what finally delivered a 35% quality lift.
Re-Forge: How We Built an AI Prose Refinement Engine
A technical deep-dive into ProseForge's rewrite system — 35 controlled experiments, catastrophic parameter failures, prompt engineering dead ends, and the architecture that finally worked.
The Problem
AI-generated prose has a quality ceiling. Every model we tested — from 3B parameter local models to 70B cloud endpoints — produces recognizable patterns: labeled emotions ("she felt a surge of anger"), recycled gestures ("his eyes widened"), and a flatness that any reader spots within a paragraph. Our automated quality assessor scored raw AI output at 5.36/10 across 87 stories, with a bimodal distribution: test stubs scored 1.6-1.9, real stories clustered between 3.5 and 9.8 with high variance.
The question wasn't whether AI prose needed improvement — it was whether a second AI pass could reliably improve it, and what it would take to get there.
Re-Forge is our answer: a post-generation rewrite pass that takes a finished story section, feeds it back through a larger model with full story context and machine-detected quality issues, and produces a refined version. The result: a 35% quality improvement (5.36 to 7.67-8.36) with a clear audit trail through git-backed version control.
This document covers the technical decisions, failed experiments, and architecture behind that number.
The Testing Methodology
The Lap System
We use a "lap" system for quality experiments — each lap changes exactly one variable, generates a story, and measures the result against the prior baseline. This is the only way to draw conclusions with high-variance stochastic systems. Key rule: never change two things at once. When Lap 28 regressed, we knew exactly which variable caused it.
We ran 35 laps over 8 days. Each lap generates a story, assesses it with our automated quality system, and records the result. Multiple runs per configuration are required — single-run results are unreliable with standard deviations of ~2.5 on a 0-10 scale.
The CLI Test Harness
Early experiments relied on the web UI, which made iteration slow and uncontrolled. We
built a CLI tool (proseforge-cli) that drives the entire pipeline from the terminal:
# Generate a story through the full pipeline
cli story generate --surprise-me --section-count 5
# Assess quality of an existing story
cli story assess --story-id <id>
# Trigger a rewrite pass
cli story rewrite --story-id <id>
# Export for manual review
cli story export --story-id <id> --format markdown --output ./test-stories/
The CLI talks to the same API as the web UI, so it exercises the real code paths — auth, credit deduction, job queue, provider cascade, WebSocket completion events. This was critical: bugs found through the CLI are bugs users would hit. We used it to run batch assessments across all 87 stories, trigger multi-pass rewrite experiments, and export stories for hand-reading.
For the quality detector calibration (Lap 33), we also built a batch assessment endpoint that runs the assessor across all stored stories and dumps results as JSON. This let us validate detector changes against a large corpus without regenerating any content.
The Full Experiment Log
Here's every lap we ran, compressed into a single table:
| Lap | Config Change | Score | Result | Key Finding |
|---|---|---|---|---|
| 17 | Baseline: story bible only | — | FAIL | Without memory of prior sections, model regenerates same content |
| 18.1 | Plot progress ON | — | FAIL | Fixes cross-section duplication but repetition loops persist |
| 18.2 | + chunk_size=500, RAG | — | FAIL | 2 LLM calls per continuation too slow for local Ollama |
| 18.3 | + skip sections <600w | — | PASS | Short-content optimization + RAG = best structural config |
| 19.2-19.9 | + StoryAssessor (8 runs) | 1.74-8.63 | Mixed | High variance — scores range from catastrophic to excellent across identical config |
| 20.4 | qwen2.5:14b | — | PASS | Model size >> prompts. 14B follows instructions 3B ignores |
| 21 | repeat_penalty=1.2 | — | FAIL | Catastrophic word-salad degeneration |
| 22-23 | Prompt fixes (rp=1.2) | — | FAIL | Prompts can't fix parameter problems |
| 24.1 | repeat_penalty=0.7 | — | FAIL | Infinite repetition loops |
| 24.2 | repeat_penalty=1.0 | — | PASS | The only safe value |
| 24.3 | repeat_penalty=1.05 | — | FAIL | Clean initially, degenerates in continuations |
| 25.1-25.3 | freq/pres penalty sweep | — | PASS | 0.1/0.1 is the sweet spot — safe with measurable benefit |
| 27 | Baseline: forbidden patterns + dialogue rules + clean params | — | PASS | 30 dialogue lines, 100% unique openings. Best baseline |
| 28 | + system prompt craft principles | — | REGRESS | 4x more tell-don't-show. Abstract principles BACKFIRE |
| 29 | + 4 new forbidden patterns | — | FAIL | Exact matches blocked but model generates equivalent variants |
| 30 | + WEAK-to-STRONG rewrite examples | 10.0 | PASS | Tell-don't-show drops ~25%. Model generalizes from before/after pairs |
| 31 | 5-section validation | — | TIMEOUT | Local qwen2.5:14b too slow (~6min/section) |
| 32 | Temperature 0.7 to 0.8 | 9.78 | REGRESS | Slop 2-4x worse, forbidden pattern violated, paragraphs over-fragmented |
| 33 | Detector calibration (3 runs) | 9.28-9.83 | — | Automated vs manual gap: ~1.3. Zero false positives |
| 34 | AI rewrite 3x targeted | 6.00 to 8.36 | +2.36 | Pass 1 = 83% of total gain. Pass 2 regressed before Pass 3 recovered |
| 35 | AI rewrite 3x generic | 6.81 to 7.67 | +0.86 | Pass 1 = biggest gain. Diminishing returns confirm: single pass is optimal |
The Catastrophic Discovery: repeat_penalty
The single most important finding in the entire quality project:
repeat_penalty > 1.0 causes catastrophic prose degeneration.
Ollama's repeat_penalty applies a multiplicative penalty per token occurrence:
logit_penalty = original_logit / (repeat_penalty ^ occurrence_count)
A token used 3 times at repeat_penalty: 1.2 gets a 1.728x penalty. After 10
occurrences it's 6.2x. Common English words — "the", "a", "is", "and" — become
increasingly unlikely. On outputs longer than ~500 tokens, the model runs out of
common words and produces word-salad.
We tested systematically:
| repeat_penalty | Effect on ~1,700 word stories |
|---|---|
| 0.7 | Infinite repetition loops — model gets stuck repeating phrases forever |
| 1.0 | Clean output, no degeneration (the only safe value) |
| 1.05 | Clean for ~500 tokens, then degenerates in continuation chunks |
| 1.1 | Ollama's default — risky for any output longer than ~800 tokens |
| 1.2 | Catastrophic — every single run produced word-salad within 500-800 tokens |
Every run at repeat_penalty: 1.2 (Ollama's default) produced gibberish. This was
initially misdiagnosed as a prompt problem — we spent Laps 22-23 trying to fix
degeneration with better prompts before isolating the parameter.
The fix was to disable repeat_penalty entirely (1.0) and replace it with OpenAI-style
linear penalties:
| Parameter | Mechanism | Our Value |
|---|---|---|
repeat_penalty | Multiplicative: logit / (penalty ^ count) — exponential | 1.0 (OFF) |
frequency_penalty | Additive: logit - (penalty * count) — linear | 0.1 |
presence_penalty | Fixed: logit - penalty (if token seen at all) — constant | 0.1 |
The linear penalties compound additively and never degenerate, even on 10,000+ token outputs. This finding is model-agnostic — we validated it across qwen2.5:14b, qwen2.5:7b, and llama-3.3-70b (via Groq). The exponential compounding mechanism affects all transformer architectures equally.
The Prompt Engineering Dead Ends
Three failed approaches taught us more than the successes.
Lap 28: Abstract Craft Principles (BACKFIRED)
We added "YOUR CRAFT PRINCIPLES" to the system prompt: "Emotion lives in the body, not in labels. Show grief through what characters do, not what they feel."
The data:
| Metric | Baseline (Lap 27) | With Craft Principles (Lap 28) | Change |
|---|---|---|---|
| Tell-don't-show instances | ~4 | ~15 | 4x worse |
| Forbidden pattern hits | 2 | 4 | 2x worse |
| Dialogue lines | 30 | 38 | +27% |
The model interpreted "emotion" and "grief" as topics to write about, producing more labeled emotions, not fewer. This is the central paradox of prompt engineering for prose quality: telling a model to "show don't tell" makes it tell more. The word "emotion" in the system prompt primes the model to think about emotions and then label them.
Lap 29: More Forbidden Patterns (MOVED PROBLEM)
We added 4 new concrete bans: "brow furrowed", "a look of [emotion] on face", "heart felt heavy", "resolve strengthened".
Compliance on exact matches was perfect — zero hits across 2 runs. But the model generated equivalent variants for every ban:
| Banned Pattern | Model's Variant |
|---|---|
| "brow furrowed" | (blocked) |
| "a look of [emotion] on face" | "apologetic look on her face" |
| "heart felt heavy" | (blocked) |
| "resolve strengthened" | "renewed resolve" |
We were playing whack-a-mole with an infinite dictionary. Reverted.
Lap 32: Higher Temperature (REGRESSED)
Temperature 0.7 to 0.8 for more creative prose:
| Metric | Temp 0.7 (Lap 30) | Temp 0.8 (Lap 32) | Change |
|---|---|---|---|
| AI slop per 1k words | 0.0-1.2 | 2.3 | 2-4x worse |
| Forbidden pattern hits | 0-2 | 1 ("heart raced") | Direct ban violation |
| Paragraphs | 21-31 | 60 | Over-fragmented |
| Text stutter | 0 | 1 | Continuation seam duplicate |
Higher temperature trades instruction compliance for creativity. When quality depends on following specific rules, that's the wrong tradeoff. We also got "Mae Chicken" as a character name — higher temperature literally produced absurd outputs.
What Actually Worked
Model Size > Everything (Lap 20)
qwen2.5:14b dramatically outperformed smaller models:
| Model | Parameters | Instruction Following | AI Slop/1k | Time |
|---|---|---|---|---|
| qwen2.5:3b | 3B | Poor — ignores structural rules | High | Fast |
| qwen2.5:7b | 7B | Moderate | Medium | 2m |
| qwen2.5:14b | 14B | Strong — follows complex rules reliably | 0.6 | 4m |
| mistral-small:24b | 24B | Strong | Low | 6m (too slow) |
The 3b model simply could not follow instructions like "don't repeat the prior section's content." Model sizing is the highest-leverage quality knob — worth more than any prompt change we tested.
WEAK-to-STRONG Rewrite Examples (Lap 30)
The breakthrough for tell-don't-show. Instead of telling the model what NOT to write (bans — Lap 29) or giving abstract principles (Lap 28), we showed concrete before/after pairs in the prompt's format block:
WEAK: "He felt a surge of anger."
STRONG: "His fist closed around the pen until the plastic cracked."
WEAK: "She was nervous about the meeting."
STRONG: "She checked her phone three times on the walk from the parking lot."
WEAK: "A wave of sadness washed over him."
STRONG: "He set the photograph face-down on the desk and left the room."
WEAK: "She felt relieved when it was over."
STRONG: "Her shoulders dropped two inches and she laughed at nothing."
Results across 2 runs:
| Metric | Baseline (Lap 27) | With Examples (Lap 30, run 1) | With Examples (Lap 30, run 2) |
|---|---|---|---|
| Tell-don't-show | ~4 | ~3 | ~3 |
| Forbidden hits | 2 | 0 | 2 |
| AI slop/1k | — | 0.0 | 1.2 |
| Assessor score | — | 10.0 | 10.0 |
The improvement is modest (~25% reduction in tell-don't-show) but reliable, and crucially it doesn't regress anything else. The model can pattern-match concrete before/after pairs where it cannot internalize abstract principles.
The Rewrite Pass Validates (Laps 34-35)
We tested multi-pass rewriting on two production stories using the CLI:
Arm A — Targeted focus (structural, coherence, polish):
| Pass | Focus | Score | Delta | Issues |
|---|---|---|---|---|
| Baseline | — | 6.00 | — | 14 |
| Pass 1 | structural | 7.97 | +1.97 | 15 |
| Pass 2 | coherence | 7.31 | -0.66 | 15 |
| Pass 3 | polish | 8.36 | +1.05 | 12 |
Arm B — Generic (no focus):
| Pass | Focus | Score | Delta | Issues |
|---|---|---|---|---|
| Baseline | — | 6.81 | — | 15 |
| Pass 1 | (none) | 8.17 | +1.36 | 12 |
| Pass 2 | (none) | 7.67 | -0.50 | 8 |
| Pass 3 | (none) | 7.67 | +0.00 | 7 |
Pass 1 delivers 70-85% of the total improvement. Both arms saw regression on Pass 2 — the rewrite model has no memory of what it already fixed and may reintroduce patterns it removed. This non-monotonic behavior means a naive "stop when score plateaus" strategy would miss gains, but it also means additional passes are a coin flip.
This informed our production architecture: a single rewrite pass, not a multi-pass pipeline.
For comparison, manual Claude-assisted rewrites scored 8.19-9.78 — still significantly better than automated rewriting. The gap is real, but the automated pass is free (bundled into every story generation) and catches the most egregious issues.

Six production stories with their rewrite pipeline passes — each story receives an original generation, a rewrite pass, and optional enrichment passes.
The Re-Forge Architecture
Context Assembly
The rewrite prompt receives the richest context window of any operation in the system. The worker assembles:
- Target section — the full text to rewrite
- Story bible — title, genre, tone, story overview, character descriptions, plot outline (from the story's git-backed metadata)
- Full story context — every section concatenated, so the rewriter can detect cross-section duplicates, repeated phrases, and continuity gaps
- Neighbor sections — the last 1,500 characters of the prior section and first
1,500 of the next, labeled for continuity:
- "Prior Section Ending (for continuity — do not repeat)"
- "Next Section Opening (for forward continuity — lead into this)"
- Machine-detected quality issues — the assessor runs before the rewrite and feeds its findings directly into the prompt as a bullet list with severity, dimension, and evidence
This is the key architectural decision: the rewriter sees everything the quality
assessor sees. It doesn't just get "improve the prose" — it gets specific issues
like [Major] tone/cross_repetition: "the weight of the moment" appears in 3 sections.
The Quality Assessment System
The assessor scores sections across 5 weighted dimensions using 12 detectors:
| Dimension | Weight | What It Catches |
|---|---|---|
| Continuity | 30% | Duplicate content across sections (Jaccard similarity), repeated openings (5-gram fingerprints), character disappearances |
| Progression | 25% | Story restarts after section 0, short sections (<100 words), weak section boundaries |
| Coherence | 20% | Format artifacts (35+ patterns), prompt leakage, paragraph structure issues (walls of text >200w, choppy <20w avg) |
| Tone | 15% | AI phrase detection (two-tier system), cross-section repetition (6-gram fingerprints), sentence length monotony, passive voice |
| Source Integration | 10% | Technical terms, URLs, @mentions leaking from source articles |
Scoring starts at 10.0 per dimension. Deductions: Critical -3.0, Major -1.5, Minor -0.5. Floor at 1.0 per dimension. Issues capped at 10 per dimension (most severe kept).
The Tell-Don't-Show Detector
This detector alone covers 7 regex categories with a dictionary of 56 emotion nouns and 44 state adjectives. Example patterns it catches:
"[Character] felt [emotion]"— "Eliza felt a surge of determination""a [sense|hint|flicker|pang] of [emotion]"— "a flicker of concern""voice tinged with [emotion]"— "voice tinged with concern""[emotion] on [possessive] face"— "confusion clear on his face""feeling [adverb?] [adjective]"— "feeling suddenly desperate""a mix/mixture of [emotion]"— "a mix of relief"
It uses paragraph-scoped dialogue detection to avoid flagging emotional language in character speech (where it's appropriate). During calibration (Lap 33), we ran 3 stories and compared automated counts against manual hand-reads:
| Run | Words | Automated | Manual | Gap |
|---|---|---|---|---|
| 33.1 | 1,759 | 4 | 5 | 1 |
| 33.2 | 1,780 | 1 | 2-3 | 1-2 |
| 33.3 | 1,704 | 1 | 2 | 1 |
Average gap: ~1.3 on single-section stories, with zero false positives confirmed via hand-read comparison. The detector is conservative — it misses more than it catches (precision > recall). This is the correct tradeoff: better to under-count than over-count when feeding issues to an AI rewriter.
We also validated against 13 multi-section stories (67 sections, 121,085 words total). Key finding: opening sections (S0) have 5x the tell-don't-show density of closing sections (S4) — likely because S0 uses the queue prompt with no prior story context, while later sections benefit from continuation context.
| Section Position | Avg Issues per Story |
|---|---|
| S0 (opening) | 3.00 |
| S1 | 1.46 |
| S2 | 1.62 |
| S3 (climax) | 2.31 |
| S4 (closing) | 0.62 |
The Rewrite Prompt
The system message is deliberately minimal — just two sentences:
You are a professional fiction editor performing a line-level rewrite.
Preserve all plot events, characters, point of view, tense, and narrative
structure. Change only prose quality.
This is a lesson from Lap 28: minimal system prompts. The more you say in the system prompt, the more you prime the model to think about those topics. The detailed instructions live in a separate format block where they function as concrete rules rather than abstract principles:
8 forbidden prose patterns:
- "[Character] felt [emotion]" — show the emotion through action instead
- "[Character]'s eyes widened" — find a different physical reaction each time
- "[Character]'s heart raced/pounded" — eliminate this cliche entirely
- "a mixture of X and Y" — pick one emotion and show it
- "couldn't help but [verb]" — just have them do the thing
- "the tension in the air" — show the tension through character behavior
- "voice steady but tinged with [emotion]" — show the emotion in what they say
- "took a deep breath" — find a different grounding gesture
4 WEAK-to-STRONG rewrite examples (the same ones from Lap 30 that proved effective).
5 dialogue rules including "characters never explain things they both already know" and "each character has a distinct speech pattern."
Word count preservation is enforced: the prompt specifies minimum and maximum word count bounds derived from the original section length. If the rewrite comes back too short, a continuation prompt asks the model to expand without losing quality. This prevents the common failure mode where a rewriter summarizes instead of refining — we saw individual sections lose up to 79% of their content without this guard.
Provider Cascade
Re-Forge uses a provider cascade with a rewrite intent hint. The cascade tries
providers in priority order, falling back automatically on failure:
| Priority | Provider | Model | Notes |
|---|---|---|---|
| 10 | Groq | llama-3.3-70b | Fastest for text, free tier |
| 20 | Gemini | Google's models | Free tier available |
| 30 | Local Ollama | qwen2.5:14b | No API costs, slowest |
Each provider receives identical parameters: temperature 0.7, repeat_penalty 1.0 (off),
frequency_penalty 0.1, presence_penalty 0.1, max_tokens 8000. The provider_hint
metadata allows the cascade to route rewrite jobs to models optimized for editing tasks.
Version Control Integration
Every section in ProseForge is backed by a git repository. Each edit — manual save, AI generation, rewrite — creates a commit with an action prefix:
| Prefix | Source | Example |
|---|---|---|
create: | Initial AI generation | create: The Dark Forest |
update: | Manual user edit | update: The Dark Forest |
rewrite: | AI Re-Forge | rewrite: The Dark Forest |
restore: | Version restore | restore: The Dark Forest |
The version history sidebar shows colored badges for each commit type — Generated (blue), Edited (gray), Re-Forged (gold), and Restored (purple). Users can select any two versions and compare them using an inline diff viewer.
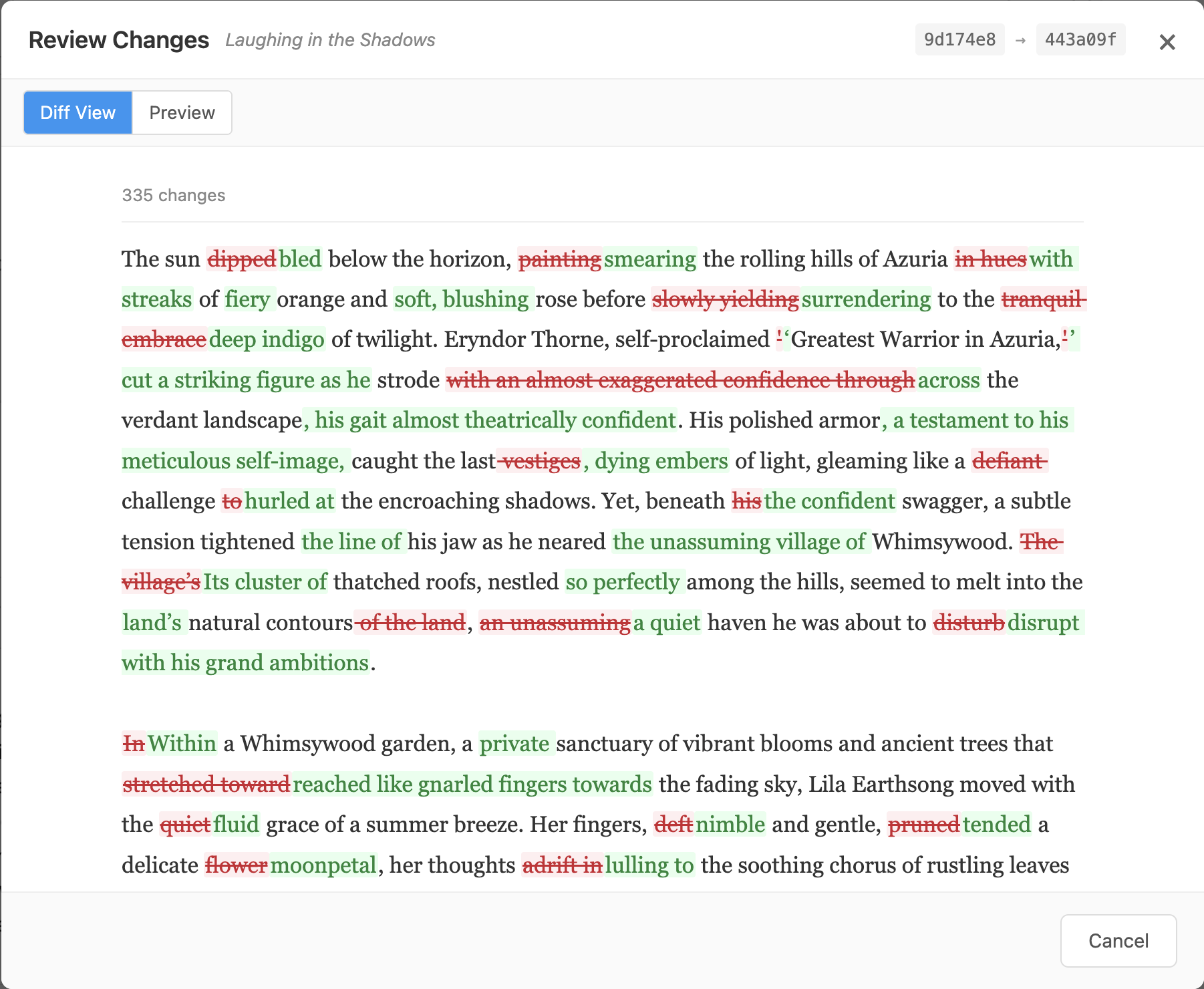
The diff viewer computes word-level diffs client-side. For prose, word-level diffs are more natural than line-level — a single word change shouldn't highlight an entire paragraph. Removed text appears with red strikethrough, added text in green.
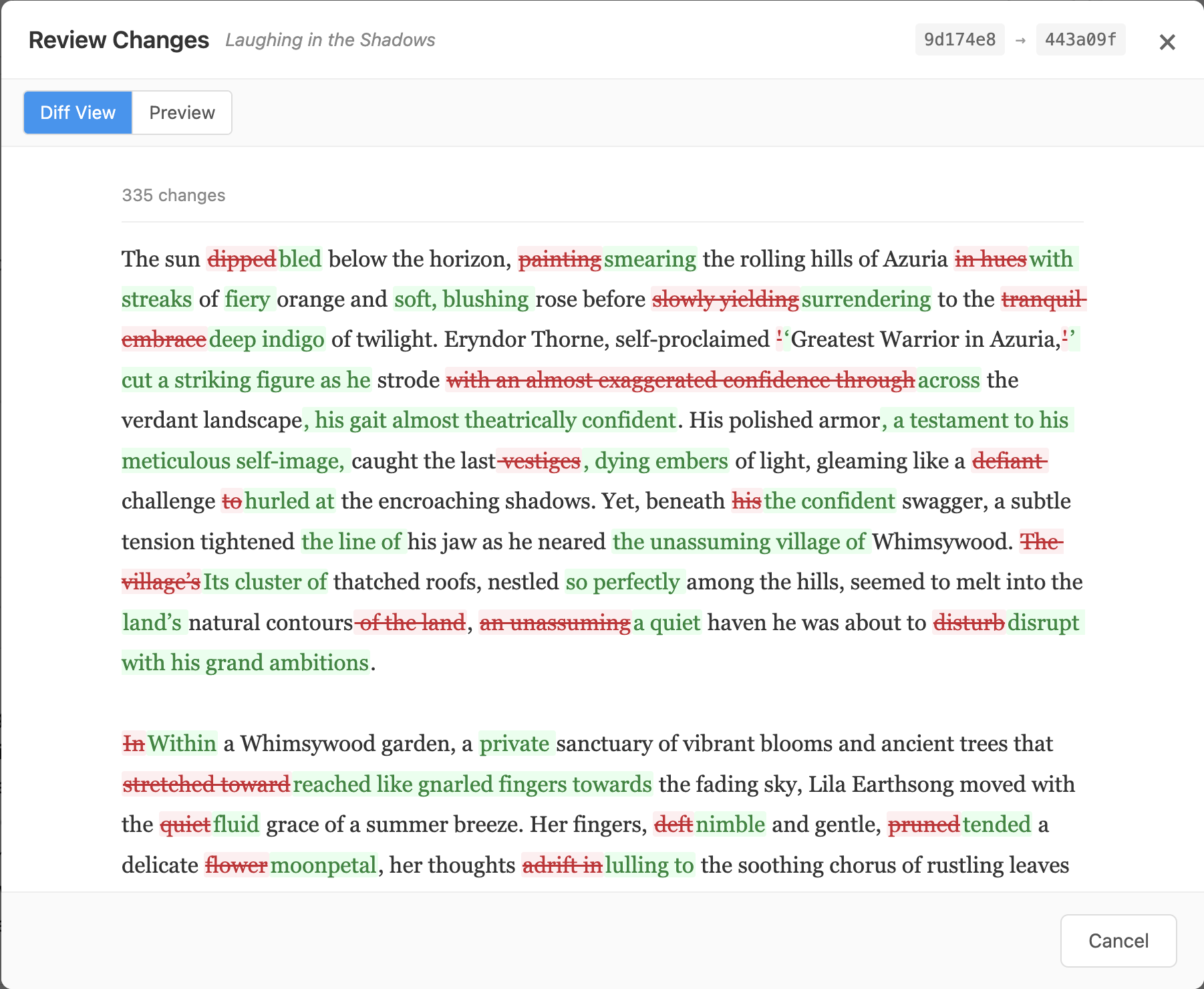
335 word-level changes from a single Re-Forge pass on "Laughing in the Shadows." Red strikethrough shows removed text, green shows additions.
The Merge Review Flow
After a Re-Forge completes, a sticky banner appears at the top of the editor: "Section was re-forged — [Review Changes] [Accept]". Clicking "Review Changes" opens the merge review panel with the inline diff. Each change can be individually accepted or rejected.
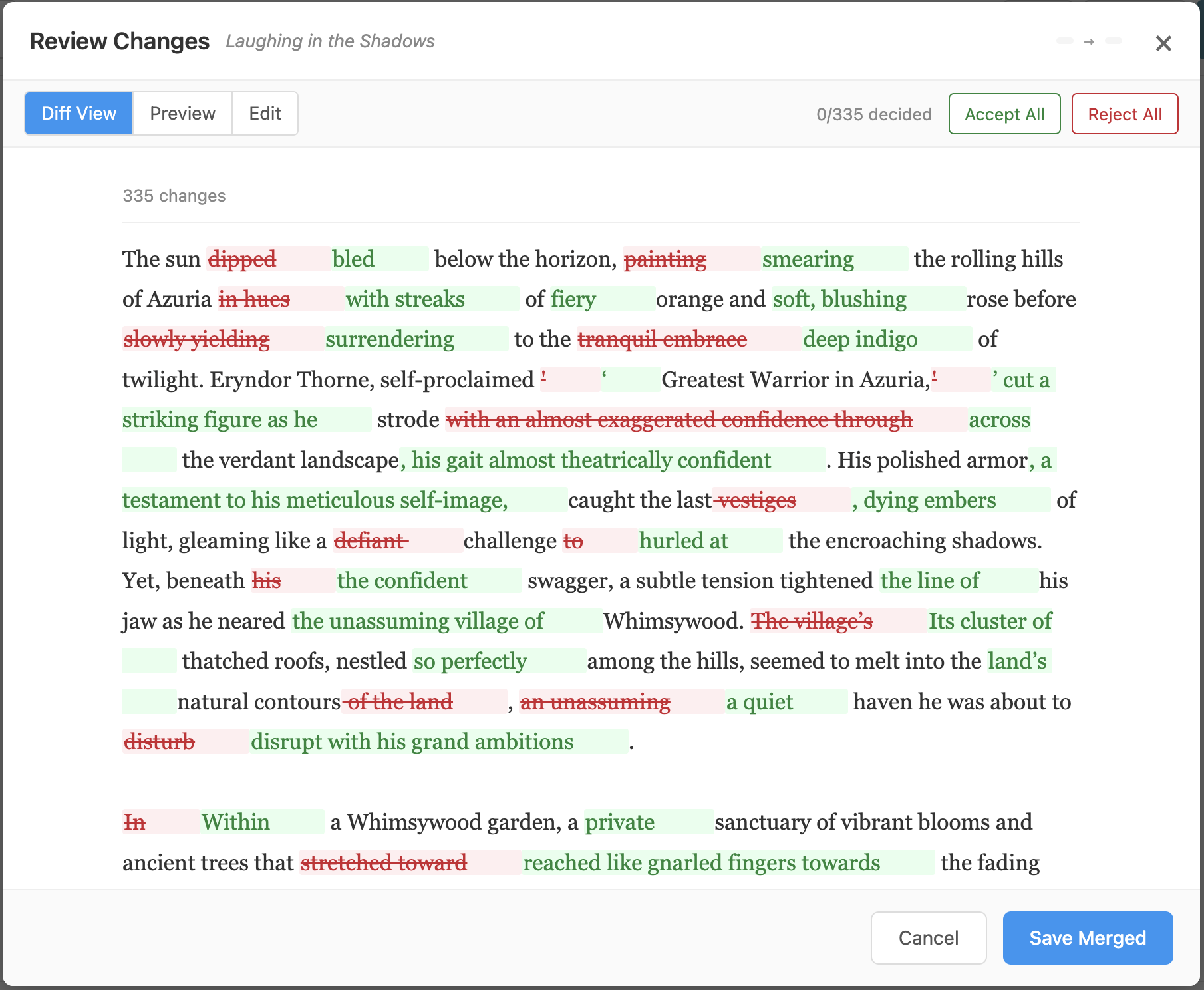
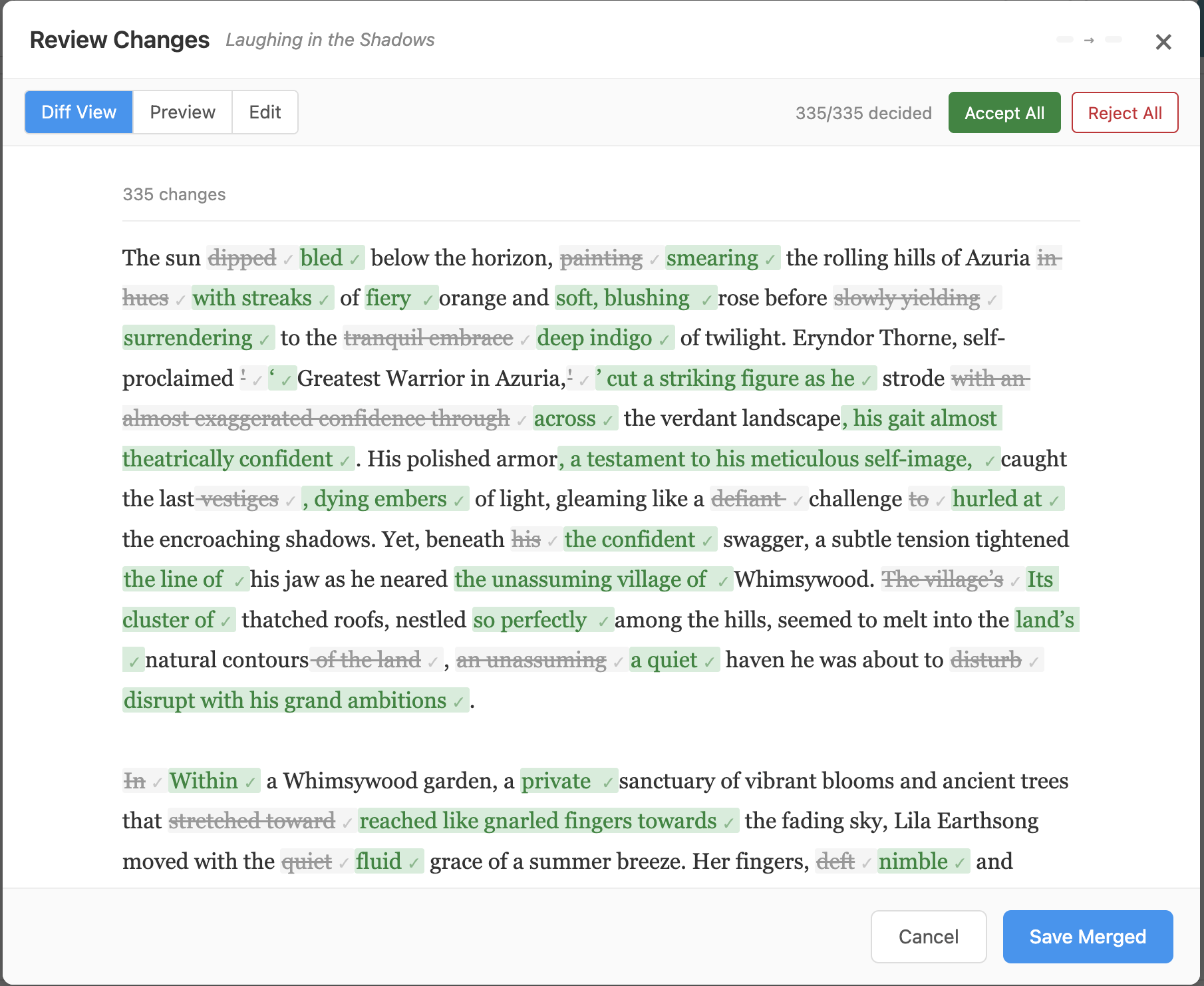
After accepting all changes — each change shows a green checkmark. "Save Merged" commits the result as a new version.
The rewrite is auto-applied (the content is already updated), so "Accept" simply dismisses the banner. If the user wants to cherry-pick changes, the merge review provides hunk-level control, and the version history offers full rollback to any prior commit.
What We Learned
The Hierarchy of Quality Levers
In order of impact:
- Model size — 14B+ parameters for reliable instruction following
- Generation parameters — repeat_penalty=1.0 is non-negotiable
- Structural pipeline — plot progress + RAG chunking prevents the worst failures
- Concrete prompt rules — forbidden patterns and WEAK-to-STRONG examples
- Rewrite pass — second AI pass with full context and quality feedback
What Doesn't Work (and Why)
- Abstract principles in prompts — "show don't tell" primes the model to tell. Use concrete bans and examples instead. (Lap 28: 4x regression)
- More forbidden patterns — the model generates equivalent variants. You're playing whack-a-mole with an infinite dictionary. (Lap 29: moved problem, didn't solve it)
- Higher temperature — trades instruction compliance for creativity. Wrong tradeoff when quality depends on following rules. (Lap 32: 2-4x more slop)
- Multi-pass rewrites — Pass 1 captures 70-85% of improvement. Passes 2-3 show diminishing or negative returns. (Laps 34-35: Pass 2 regressed in both arms)
- repeat_penalty > 1.0 — exponential compounding causes catastrophic degeneration on long outputs. No exceptions. (Laps 21-24: every value above 1.0 failed)
What Does Work
- Concrete before/after examples — the model generalizes from WEAK-to-STRONG pairs better than it internalizes abstract principles
- Full story context in rewrite window — cross-section duplicate detection requires seeing the whole story, not just neighbors
- Machine-detected issues fed into prompts — specific evidence like
[Major] tone/cross_repetition: phrase appears in 3 sectionsgives the rewriter targeted instructions instead of vague "improve quality" directives - Single rewrite pass — captures most improvement without the regression risk of additional passes
- Git-backed versioning — every change is auditable, reversible, and diff-able. Users never lose work to a bad rewrite
The Remaining Gap
Quality scores improved from 5.36 to 7.67-8.36, but the ceiling is real:
- Tell-don't-show still appears ~1-3 times per section
- Continuation seams can produce scene restarts
- Opening sections have 5x the tell density of closing sections
- The automated detector has a ~6-point gap vs manual assessment on multi-section stories (catches 6 of ~12 instances in our hand-read validation)
- Word count shrinkage is a problem — rewrites lost 16-22% of total words across our test stories, with individual sections losing up to 79%
The next frontier is voice anchoring (best paragraphs as style reference in continuation prompts), detector expansion (language contamination, verbatim section-start copying, meta-narrative intrusion), and stronger word count enforcement in the rewrite prompt.
Summary
Re-Forge started as a simple question — can a second AI pass improve prose quality? — and turned into an 8-day, 35-experiment investigation that uncovered a catastrophic parameter bug (repeat_penalty), proved that abstract prompt engineering backfires for prose quality, and validated that concrete examples and machine-detected feedback produce reliable improvements.
The system now runs in two modes. Every generated story receives a free automatic rewrite pass as part of the pipeline — generate sections, assess quality, rewrite with full context and detected issues, commit to git. Authors can review the diff in version history to see exactly what the rewrite changed. Optionally, a user can initiate an additional Re-Forge at any time — per-section or story-wide — at a credit cost. This second pass produces a merge review panel where the author can accept, reject, or cherry-pick individual changes before saving. A single rewrite pass reliably delivers +1.3 to +2.0 quality points — not perfect, but measurable, auditable, and under the author's control.