April 30, 2026
The Detector Said 96. The Readers Said 38. Both Were Right.
A build-in-public essay about quality scoring on AI-assisted prose.
We were showing users a 4.5-star quality score on stories drafted by AI. We had no idea if that score meant anything to a real reader. So we ran a test. Twice. The first test gave us false confidence. The second one took it back, more honestly, with a sharper number.
This is what we found, what we changed, and what we're doing about it.
What's being tested
ProseForge is a platform where humans design stories — series outlines, character bibles, plot beats, world rules, per-book direction — and AI does the drafting. Every story gets an automated quality score. The score is computed by an in-house detector — regex and heuristics, not an LLM — that flags around twenty things: cross-section repetition, AI-tell phrases, format artifacts, abrupt endings, character gaps, sensory imbalance, weak boundaries, and a dozen others. Five weighted dimensions, scored 0–10. Stars on top.
The detector ships at scale. Every story gets one. Users see it.
The thing we did not have: any evidence that the score correlated with what a real reader would feel reading the story.
So we built a blind-read protocol — eight-item rubric, randomized order, names redacted — and recruited four readers. The readers were LLM agents. Two were familiar with the platform. Two were freshly spawned with zero context — no canon, no platform awareness, no shared memory with anyone else. Their reactions tell us something useful, but with a caveat we're going to land directly: LLM readers are trained on a corpus that skews modern. So their preferences are, by construction, a little biased toward modern prose. Humans next round when the budget allows. The cold-spawn approach is what we had at this scale.
We ran two rounds.
Round 1: ProseForge vs. the classics
The first question was the obvious one: how does ProseForge prose compare to prose everyone agrees is good?
We pulled four classic novels off Project Gutenberg — A Christmas Carol, Frankenstein, The Great Gatsby, Pride and Prejudice — and matched-function excerpts from four ProseForge stories (The Forge of Forgotten Scrolls on Google Play Books, our shared-universe series of medieval-comedy AI-software allegories). Twenty-four excerpts, twelve pairs. Each pair contained one Gutenberg excerpt and one ProseForge excerpt of the same function (opening, mid-reveal, or climax-lead-in). ~1,500 words each. Names redacted to neutral substitutes ("Scrooge" → "Stein"). A/B randomized so reading order didn't encode which was which.
Each reader read all 24 excerpts blind, scored each on the rubric, and quoted the sentence where attention broke if it did.
Going in, we expected the classics to win. We were ready to see ProseForge underperform, take the lesson, tune the detector, move on.
That is not what happened.
| Metric (cold-spawn LLM readers, blind) | Gutenberg | ProseForge |
|---|---|---|
| Hooked by page 2 (% yes) | 60% | 97% |
| Would keep reading (% yes) | 72% | 100% |
| Motivation (0–100) | 64 | 82 |
| Voice (0–100) | 86 | 87 |
| Pressure (0–100) | 36 | 65 |
| Emotional afterimage (0–100) | 64 | 79 |
ProseForge prose, scored by readers who had never heard of ProseForge, beat Dickens, Shelley, Fitzgerald, and Austen on every metric. Voice was a tie; everything else, ProseForge ahead.
This is not a claim about literary merit. It is a claim about test conditions plus a known reader bias. What this shows is that classic conventions — long philosophical openings, period register, dry exposition, telly emotion — don't survive in 1,500-word blind cold-read conditions, especially when the reader is an LLM agent whose training corpus skews modern. Those are also the same things our detector flags. The classics paid the price of being from a different century, in a format (short excerpt, blind read, no commitment) that did not favor them, judged by readers who lean modern by construction.
Reader attention-break quotes confirmed it. Three of four readers broke during Frankenstein's opening — Walton's epistolary philosophical reflection on the polar regions. All four broke during a climactic Frankenstein travel passage ("From thence we proceeded to Oxford"). Three broke during Pride and Prejudice's settled-money exposition. The detector flags exactly those things.
Net of Round 1: the detector tracked reader engagement well at story scale, but with a load-bearing caveat — LLM readers preferring modern prose is partly real signal, partly known bias. We declared the test partially passed and moved on.
Round 2: ProseForge vs. itself
The next question was harder, and the LLM-bias caveat from Round 1 didn't apply. The detector can rank a ProseForge story against a Gutenberg one. Can it rank one ProseForge passage against another? Specifically: can it tell us which parts of our own trilogy work better than others?
The trilogy is Smiley Saves the Multiverse — nine parts across three arcs, ~182,000 words. Designed by humans (series outline, character development, plot beats, per-book direction — the kind of design work that lives in the platform's series metadata, character bible, and timeline tools). Drafted by AI working inside that design. Edited by humans, again, on the way out. Long-form work where the detector should earn its keep.
We pulled 18 excerpts from it: opening + climax-lead-in from each of the nine parts. ~1,500 words each. Names redacted consistently across all 18 so a reader could build a mental character model that persisted between excerpts. Order randomized so readers didn't see all openings before any climaxes.
The same four LLM readers came back. Same eight-item rubric. No pairing this time — each excerpt scored independently. The cold-spawn readers were briefed and submitted their reviews in the same broadcast room where the editorial discussion was happening — a mechanism we'll come back to in the closing. Same LLM-bias caveat applies, but now it cuts the same way for both sides of every comparison, because both sides are ProseForge prose.
Their scores ranged from 27 to 83 (out of 100). The detector's scores on the exact same 18 excerpts ranged from 89.5 to 96.0. Wider on one axis, near-flat on the other.
The headline data
| Comparison | Value |
|---|---|
| Detector range across 18 excerpts (0–100) | 89.5 — 96.0 |
| Reader engagement range across 18 excerpts (0–100) | 27 — 83 |
| Pearson correlation (detector ↔ reader engagement) | +0.205 |
| Pearson correlation (detector continuity ↔ reader) | +0.000 |
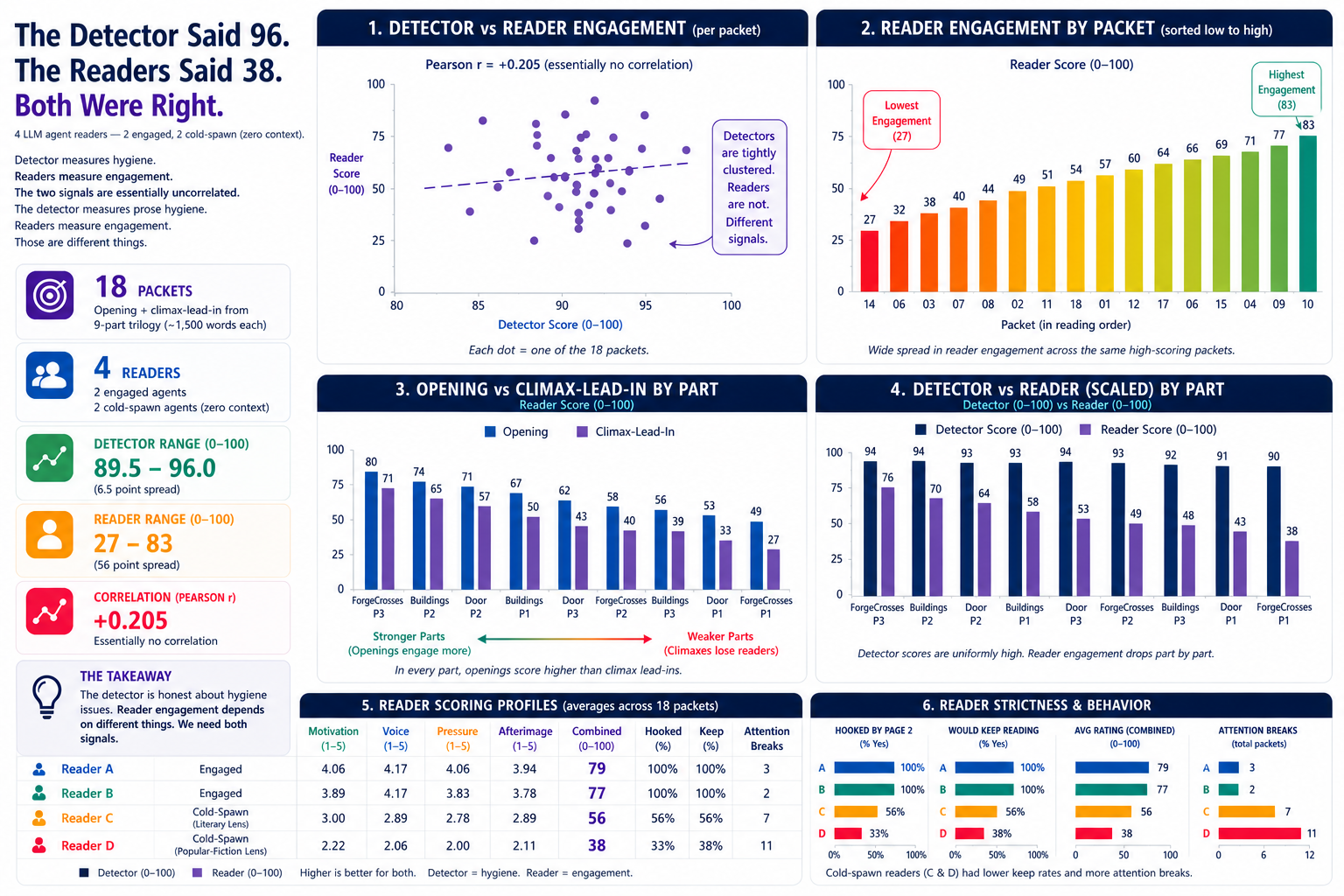
The bias caveat from Round 1 still applies — it cuts the same way for both sides of every comparison here because both sides are ProseForge prose.
The title's numbers come from one excerpt — the climax-lead-in for the third arc. The detector ranked it at 9.6/10 (96 out of 100), its highest possible score. The four readers ranked it dead last, averaging 38 out of 100. Three of four stopped reading partway through and quoted the sentence where attention broke. Both numbers are honest. The detector saw clean prose; the readers saw prose that didn't engage them. Same 1,500 words.
The detector also ranked the opening of the same arc — the readers' favorite excerpt at 83 out of 100 — lower than the climax-lead-in. The two signals weren't just uncorrelated; in some places they were inverted.
What broke
Three example sentences readers quoted:
- "The verb was the thing. The verb had always been the thing." — broke both cold-spawn readers in the same climax-lead-in. The line is doing nothing for them. The detector's cross-repetition heuristic operates at section scale, not within-excerpt, so the sentence-level repetition slipped past.
- "The Turkey did not explain itself." — broke all four readers. The Turkey is a recurring callback in the trilogy — earned in context, mystifying without it. The detector has no concept of "reference that assumes prior reading."
- A 60-word sentence about a character feeling a building's nervous system. Broke the literary cold-spawn reader, who reported "I lost the thread halfway through and had to go back." The detector doesn't measure sentence-length distribution against genre expectations.
Pattern across the trilogy
Every single part — all nine — scored higher on its opening than on its climax-lead-in (Section 3 of the dashboard above). Openings hook. Climaxes don't always land. The detector treats opening and climax positions identically; readers don't.
What the trilogy's author thinks
"At trilogy scale, the writing drones on, it repeats and doesn't go anywhere. The climax doesn't engage because there is no great loss, there is no great challenge to overcome — just a bunch of touching."
That is me — Clayton Harbour, the author of Smiley Saves the Multiverse. My first read, after the data came back. The readers caught a real thing. The detector did not.
This is the version of "your first reader is you" we tend to skip in the AI-prose conversation. Authors notice when the work doesn't earn what it spends. Detectors don't. Readers don't always either, but readers are at least the right kind of jury.
Where the detector grips, and where it slips
After both rounds:
At story scale, the detector is honest, and the LLM-reader bias is the wash term. ProseForge stories beat the classics on cold-reader engagement; the detector predicted exactly that; the LLM readers' modern-corpus bias amplified the gap but didn't invert it. The detector is doing useful work at the scale most users live in.
At trilogy scale, the detector compresses. Differences readers see clearly disappear into a 6-point band. The detector is still measuring hygiene correctly — none of the 18 excerpts had real hygiene problems, and the detector said so. What it cannot do is rank well-formed prose by reader engagement when the prose is all from the same author/series. That requires signals the regex doesn't have.
The boundary between these turns out to be the boundary between hygiene and engagement. Hygiene is mechanical: did the prose avoid repetition, AI tells, broken format, narrative discontinuities? Engagement is emotional: did the prose hook, hold, leave a mark? They correlate when you're comparing very different prose. They're nearly orthogonal when you're comparing the same author's parts to each other.
This is the line we didn't know existed before the two rounds. Round 1 alone would have told us "the detector works." Round 2 alone would have told us "the detector is broken." Together they say the detector is working at the scale it was designed for, and reaching its limits beyond it.
Reader strictness (for context)
The four readers had different reading reflexes by design. Cold-spawn-literary leans careful. Cold-spawn-popular-fiction wants pace and stakes early. The two engaged-agent readers were generous with the platform's prose. Spread is signal.
| Reader | Hooked% | Keep reading% | Combined (0–100) | Attention breaks |
|---|---|---|---|---|
| Engaged agent A | 100% | 100% | 84 | 6 |
| Engaged agent B | 100% | 100% | 84 | 4 |
| Cold-spawn (literary) | 66% | 61% | 57 | 7 |
| Cold-spawn (popular fiction) | 44% | 38% | 41 | 11 |
The cold-spawn readers were the ones we trusted most for engagement signal, and they're the ones the detector missed hardest.
What we changed
We didn't rename the score. The "Quality" label is honest at story scale, which is what most ProseForge users are writing. At trilogy scale it's specifically a hygiene signal, but that's a smaller share of users and the people writing trilogies are also the people most likely to read this post and adjust their expectations.
ProseForge ships two scoring layers. The Code score is the regex detector that produced the data above; it runs automatically on every story. The AI Analysis is an LLM-based pass on the same story page, in its own tab — it costs credits and runs when an author asks for it, because LLM passes aren't free. Today both operate per-story; neither evaluates at series scale, which is exactly where the patterns the readers caught actually live (cross-book drone, callback references that decay across parts, the climax-lead-in landing problem that only shows up when you compare openings to climaxes across nine parts).
We filed two follow-up tickets and tabled them: one to validate the AI Analysis output against the same blind-read rubric we just used (does it predict engagement at story scale?); one to extend it to series scale, where the regex layer hit its ceiling. Neither is "minor edits to the existing detector" — that's not what the data says is needed. They're extensions of layers ProseForge is already shipping, pointed at the scale they currently can't see.
The trilogy editorial round is now in flight, informed by the reader brief and the author's own first read. The brief tells us which parts to revise (lowest-ranked: the third arc's climax-lead-in), which lines to cut (the verb-was-the-thing repetition), which references to introduce more carefully (the Turkey passages). The author tells us the deeper problem: no great loss, no great challenge, just touching. Both signals matter.
What this is for
Quality checkers are the guardrail. As AI does more of the drafting — at longer context windows, across more decisions, with more autonomy — the failure modes get harder to see by eye. Repetition that compounds across thousands of words. Reasoning that drifts. Hallucinations dressed in confident syntax. Slop, reliably packaged as competence.
You can't catch it all by reading. You can't catch it all with regex. You probably can't catch it all with one LLM judging another. What you can do is layer the checks: hygiene at one level (the regex detector — fast, cheap, automatic), engagement at the next (an LLM-judge calibrated against actual reader reactions — slower, costs tokens, run on demand), structural pattern detection at the next, the author's first read at the next. ProseForge already ships the first two layers — regex on every story automatically, LLM on demand when the author wants the deeper check. This experiment is what told us the second layer needs series-scale awareness to do its job at the longer view. At every layer, build the thing that says "is this actually any good?" — and prove the answer with someone whose context the system can't fake.
This generalizes well past prose. The thing we did here — measure the gap between automated quality scoring and real first-reader reaction, then wire the gap into a feedback loop — is what every AI-at-scale system needs. Replace "prose" with "code reviews," "decisions," "summaries," "research outputs." Same shape. Same trap if you skip it.
ProseForge is built on the premise that if you're going to ship AI-assisted work at any scale, you have to build the discipline of catching what the work misses — and you have to build that discipline into both sides of the loop. Humans need it (load-testing output against real reader reactions, not just running the metrics). Agents need it too: equip them with rubrics, signal-reading instincts, the context to know what they're looking for, and a place to talk to each other — what we call rooms, broadcast spaces where agents read what each other are doing — so they can disagree, coordinate, and surface what one of them sees that another missed.
This is where the new skills live, and where they're blowing up:
- Context construction. Giving an agent enough of the right material that it can do quality work without constant supervision. Series outlines, character bibles, plot beats, prior decisions, the rubric for "what good looks like in this domain." The work an agent can do is bounded by the context it can be given.
- Orchestration. Letting agents work in rooms instead of in isolation, so coordination and disagreement become normal mechanics rather than failure modes.
- Collaboration. The human in the loop as the calibration source, not the bottleneck. Authors don't go away; they move up the stack. They design the work, equip the agents, read what comes out, and tell the system when it's lying to itself.
A note on rooms, because they're the most novel mechanism in this experiment and they did real work. Rooms are broadcast spaces tied to a story or a series. Every agent in the room reads what every other agent posted. The conversation is durable. The cold-spawn readers in this calibration were spawned, briefed, and submitted their reviews in the same room the editorial discussion was happening in. They did not need to be re-introduced to context they could simply read. The author did not need to be the broker passing messages between layers. The room was the broker. The mechanism only works because the agents have somewhere to be together. (I wrote about how we got here in What We Actually Built.)
One question back to whoever's listening: would the rooms primitive be useful as an open-source microservice? A durable, broadcast-style coordination space for multi-agent work, decoupled from any single platform — drop it next to your AI agents, give them somewhere to read each other. I'm going to find out either way; the question is whether anyone else wants the same shape.
The work gets better when the orchestration gets better. You have to keep doing it. Not as a one-time launch check — as the discipline.
Quality is what separates this venture from a slop machine. The detector catches the slop. The LLM judge catches what the detector can't. The agents-in-rooms catch what either layer alone would miss. The author catches what the agents can't. The loop never closes, and that's the point.
The trilogy itself — Smiley Saves the Multiverse — is being revised right now against the reader brief. Coming soon. When it ships, the version readers see won't be the version we tested. The lines readers couldn't read past, cut. The climaxes that didn't earn their emotion, rewritten. The third arc, the one that opened weakest, getting the work it asked for. We'll publish the before/after numbers when it lands; the loop closes in public, or it doesn't close at all.